Submit and Monitor Pipeline Batches (Tutorial)
| Abbreviations Key |
| AIFI | Allen Institute for Immunology |
| CLI | command line interface |
| HISE | Human Immune System Explorer |
| QC | quality control |

At a Glance
To ensure efficient resource allocation and reliable, reproducible results, it's important to follow established procedures for batch submission and processing. This tutorial outlines those procedures and shows you how to retrieve results and troubleshoot issues.
Instructions
 Find and open the correct watchfolder
Find and open the correct watchfolder
1. Navigate to HISE, and use your organizational email address to sign in.
2. In the upper-right corner, click your name.
A. Click Environment.
B. On the Configure HISE Environment page, select the Accounts tab.

C. In the Available Projects field, select the account and project you want to use. To select or deselect all available projects, select or clear the checkbox to the left of the Name column.

3. In the upper-right corner, click your name.
A. Choose Watch Folders.
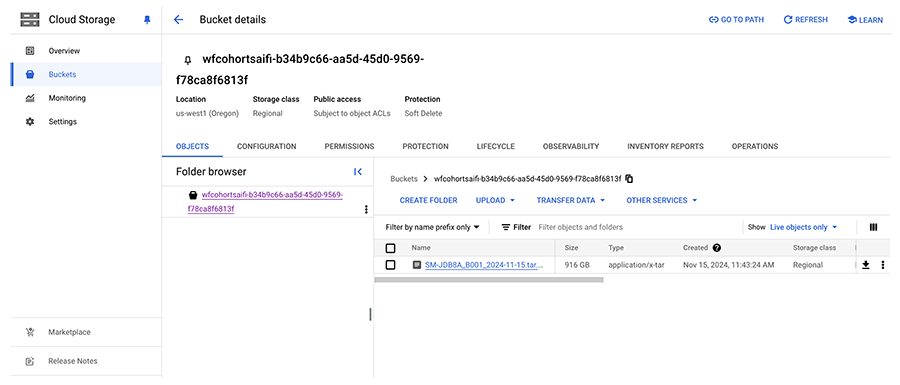
B. On the Watchfolders page, find the watchfolder you want to work with, and click its name.

C. A cloud storage bucket opens. Upload all required batch files to this folder.
 Submit a batch
Submit a batch
1. Upload a submission sheet to the watchfolder:
A. Confirm that the file name syntax matches the current naming convention for your batch’s sequencing type. See the following note.
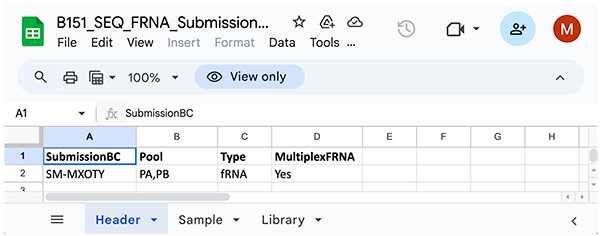
Inaccurate syntax can cause errors during pipeline runs. For details, see Pipeline File Syntax. The submission sheet also requires standardized syntax, especially in the Type column of the header sheet. Be sure to double-check the placement of spaces. A sample submission sheet is shown below.
|
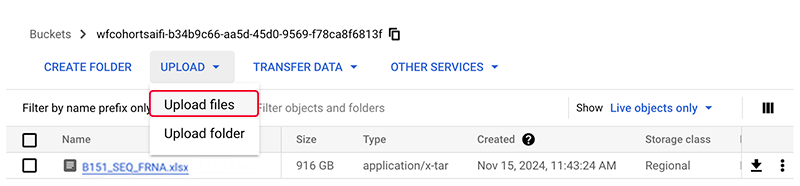
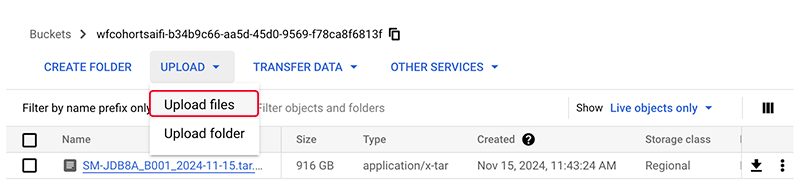
B. In the watchfolder you selected, go to UPLOAD > Upload Files.
(Optional) Alternatively, drag your file into the selected watchfolder.

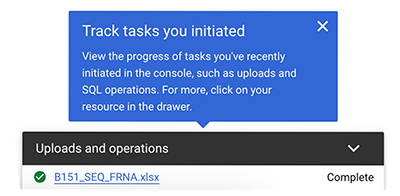
C. To view your uploaded file data, click Uploads and operations in the lower-right corner of your screen.
D. (Optional) Resubmit your submission sheet (to correct an error, for example):
i. To request deletion of the original sheet, email the dev team (madeline.ambrose@alleninstitute.org).
ii. To submit your corrected sheet to the watchfolder, follow the process outlined above.
 Submit a tar file
Submit a tar file
1. Before you begin, install the Google Cloud CLI. As you prepare your tar file, be sure to follow the required syntax.
2. In your terminal, enter the following command:
gsutil cp gs://yourBucketName/YourFileName gs://WatchfolderBucket
This command copies data from the source cloud storage bucket to the destination bucket without first downloading the data locally.
3. Save your tar file to your local machine, and upload the file to your watchfolder, as described in 1B of Step 2.
 Use the pipeline dashboard to monitor your batch
Use the pipeline dashboard to monitor your batch
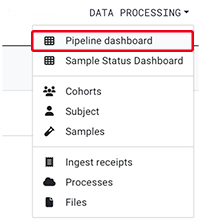
1. In the pipeline dashboard, you can view the status of each process in the pipeline run, find input/output files, and review error logs if problems occur. When a pipeline run is complete, or if a process fails, you're notified by email. To view the dashboard, go to the main navigation menu in HISE, and select Data Processing > Pipeline dashboard.
2. To filter by Pipeline type, Batch ID, Panel ID, Samples complete, Status, Ingest receipt, Submission file, Project ID, or Audit info, use the dashboard tabs.
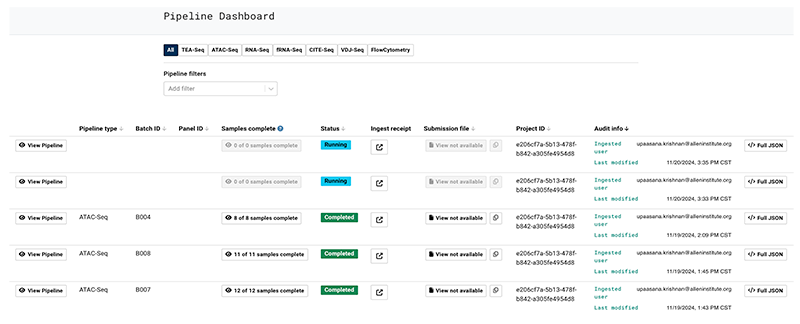
A. To make sure your file was uploaded correctly, click Ingest receipt.

B. To see the details of each process in your batch’s pipeline run (as shown in the following image), click View Pipeline in the far left column of the dashboard.
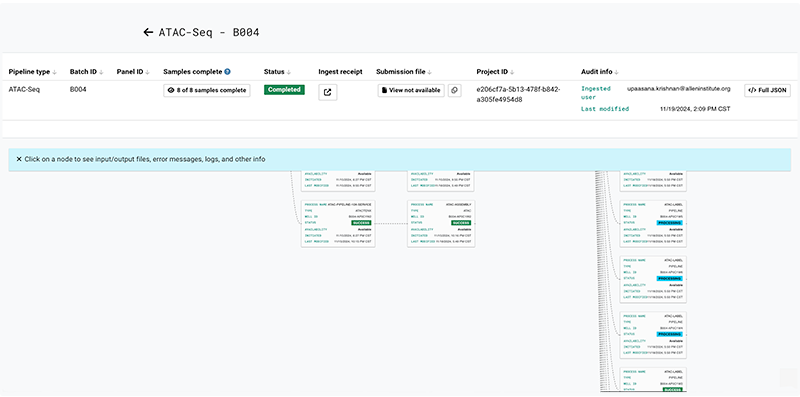
i. To see a different part of the pipeline on your screen, click, hold, and drag the pipeline image. The visible portion of the image is highlighted in the React Flow mini map.
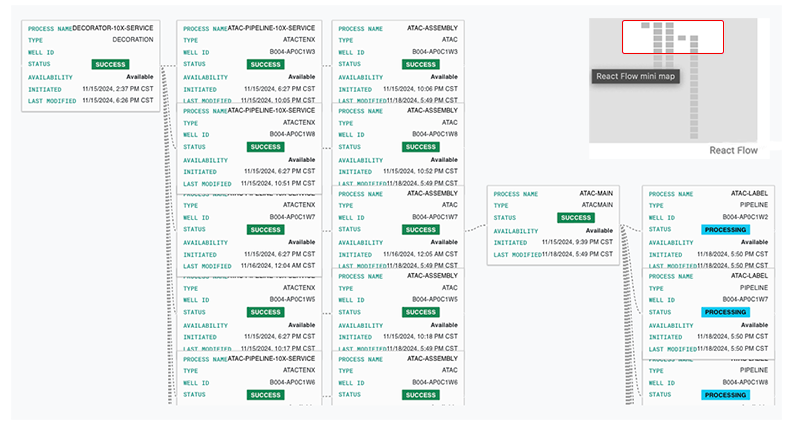
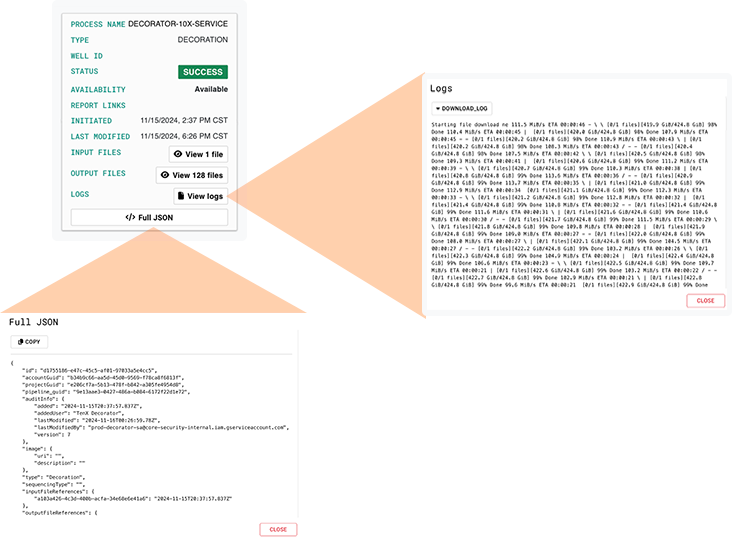
ii. Click to expand any node, and click View logs or </> Full JSON to see the complete logs or the entire block of JSON code, respectively.
3. (Optional) To retry a failed pipeline process, click Status > Retry pipeline.
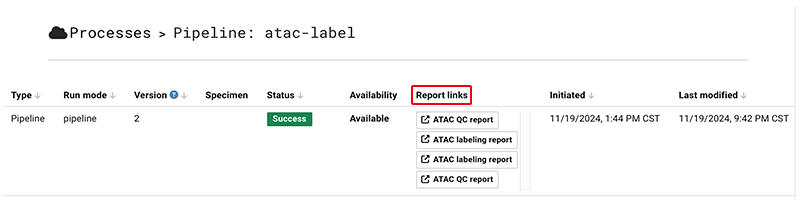
4. Review the quality control report for a given pipeline:
A. Go to Data Processing > Processes > [Process name].
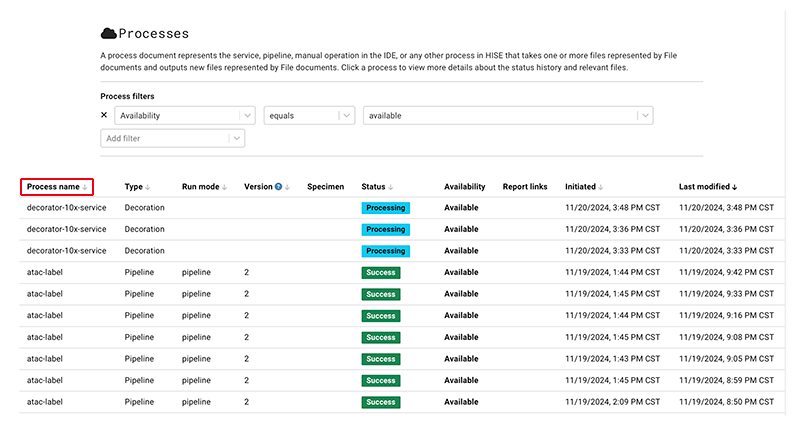
B. On the Processes > [Process name] page, in the Report links column, click the QC report for the process you want to view.
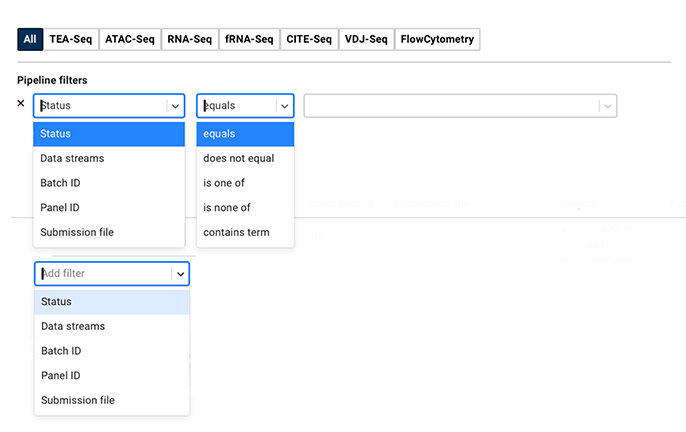
5. To find your batch in the dashboard, use the filters and boolean options, or add your own filter.
 View pipeline result files
View pipeline result files
1. When a run is complete, you can perform an advanced search to access the results files.
A. From the main navigation menu in HISE, select Research > Advanced Search. T
B. The most common filter for result files is batchId. To use the batchId filter, open the Sample Metadata menu. For details, see Use Advanced Search (Tutorial).
 Rerun a batch
Rerun a batch
1. From the main navigation menu in HISE, go to Data Processing > Sequencing pipeline approval.
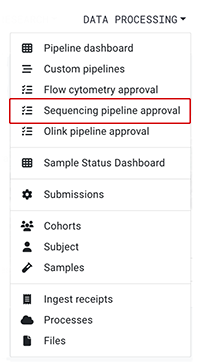
2. On the Sequencing Approval page, in the Submission ID column, click the submission ID for your batch.

3. Click Flag as duplicate. This process can take some time. We recommend you wait at least 10 minutes to avoid errors that occur when a batch is rerun without the flag in place.

4. Rename your tar file, which gives the file a new timestamp, and return your project watchfolder to upload the file. If you don't rename the file, it'll be rejected as a duplicate upload.
 Troubleshoot process failures
Troubleshoot process failures
If a process fails, follow the instructions below to debug the error.
1. Review the process logs to pinpoint where the process failed (see Step 3B, above). Note any errors in the R/Python code.
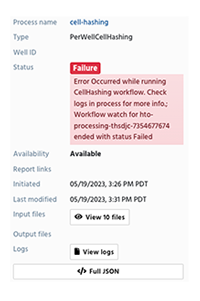
2. If you can't troubleshoot the error, or if the logs are blank, contact us for further assistance (immunology-support@alleninstitute.org).
 Related Resources
Related Resources
Configure a Pipeline (Tutorial)
Understand Automated Pipelines
Use Watchfolders to Ingest Data (Tutorial)