Use the Upload Files SDK Method (Tutorial)
Last updated 2026-06-17At a Glance
This document explains how to upload files—for example, cleaned datasets, analysis outputs, summary tables, or visualizations—to a study in the HISE Collaboration Space.
NOTE
HISE automatically creates file sets from your uploaded files in an upload_files SDK call unless you disable this behavior. If you prefer not to have file sets created automatically, set the no_file_set parameter to True. The default is False. If not declared, a file set containing the uploaded files will be created in your study space.
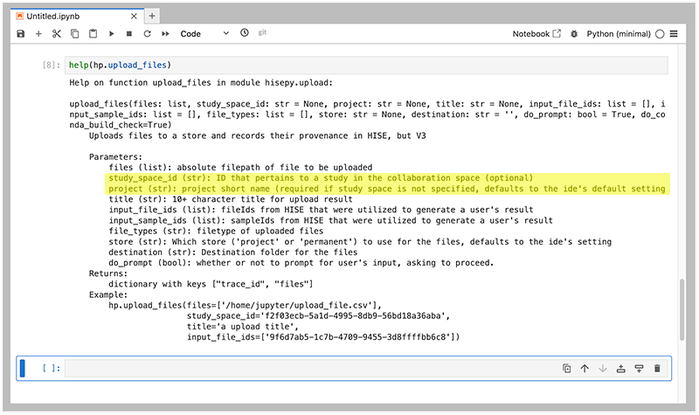
The upload_files() signature is shown in the box below, and the method parameters follow. If you have questions, contact Support.
Method Signature
The signature for this method is listed below. Click the tabs to toggle from Python to R.
Python signature
hp.upload_files(
files: list,
study_space_id: str = None,
project: str = None,
title: str = None,
input_file_ids: list = [],
input_sample_ids: list = [],
file_types: list = [],
store: str = None,
destination: str = '',
do_prompt: bool = True,
do_conda_build_check = True,
use_fast_mode = False,
no_file_set = False
)R Signature
uploadFiles(
files,
studySpaceId = NULL,
project = NULL,
title = NULL,
inputFileIds = list(),
inputSampleIds = list(),
fileTypes = list(),
store = NULL,
destination = NULL,
doPrompt = TRUE,
doCondaBuildCheck = TRUE,
useFastMode = FALSE,
noFileSet = FALSE
)Parameters
The parameters for this method are listed in the following table.
Parameter | Data type | Required or optional | Description | ||
|
| required | List of file paths to upload. | ||
|
| required | ID of the upload destination (study space or workspace). | ||
|
| required | Title or description of your choice. For naming conventions that support autostacking, see Step 1 of Create an IDE Stack (Tutorial). | ||
|
| required | Input file IDs associated with this upload call (to track data provenance). | ||
|
| optional | Project name or ID. | ||
|
| optional | Input sample IDs associated with this upload. | ||
|
| optional | List of file types included in the upload. | ||
|
| optional | Name of Project Store or other backend storage location. | ||
|
| optional | Destination path or folder | ||
|
| optional | Specifies whether to prompt the user for confirmation before uploading. | ||
|
| optional | Specifies whether to create and build the active Conda environment. Default is | ||
|
| optional | Specifies whether to speed up the upload flow by skipping the step that builds the IDE environment. Default is | ||
|
| optional | Specifies whether a file set is created when the files are uploaded to the study space. Default is |
Parameter | Required or optional | Description | ||
| required | List of local files to upload. | ||
| required | UUID of the study space to which these files should belong. | ||
| required | Title of the track record. | ||
| required | UUIDs of files that provide data for these files. | ||
| optional | Project for the files. Required if study space ID is not provided. | ||
| optional | Other samples that provide data for these files. | ||
| optional | File types for the uploaded files. Default is the file extension. | ||
| optional | Which store to upload to: either | ||
| optional | Destination folder into which the file is uploaded. Ignored if using the permanent store. | ||
| optional | Specifies whether to prompt for user input. Default is | ||
| optional | Specifies whether to create and build the active Conda environment. Default is | ||
| optional | Boolean that specifies whether to speed up the upload flow by skipping the step that builds the IDE environment. Default is | ||
| optional | Specifies whether a file set is created when the files are uploaded to the study space. Default is |
 Get Help
Get Help
If you get stuck during an upload_files() call, refer to the steps of this tutorial (examples are in Python unless otherwise specified). To use the baked-in help in your IDE, try one of the following commands. Still not working? To file a ticket, click Collaboration Space. Doing so lets you share your insights with others. The upload_files() signature is shown in the box below, and the method parameters follow. If you have questions, contact Support.
Python | R | Output |
|---|---|---|
|
| Function signature, list of parameters, class, and a brief description of the method in a compact plain-text format |
|
| Method signature, docstring (description), file location, and file type in more readable format |
|
| Signature, docstring, file path, a verbose set of metadata, and the source code for the method |
Instructions
 Get the study space ID
Get the study space ID
Each study in any given project is assigned a study space ID. This unique ID ensures that your uploaded files are saved to the correct study in the Collaboration Space. The study space ID (recommended) or project name is one of the four parameters required in an upload_files() call. For details, see the Tips & Trick section on this page. Refer to the accompanying table for a full list of required and optional parameters.
1. Open an IDE and find your study space ID by entering the following code. A list of dictionaries is returned.
# Return all available study spaces for your account
ss_output = hp.get_study_spaces()
2. To search for the study you want, enter the following line. In this example, we look up a study titled "Sample Study."
# Find the name of a particular study space
ss_name = 'Sample Study'
for study_space in ss_output:
if study_space['name'] == ss_name:
ss_obj = study_space
# Show the matching study space dictionary
ss_obj
3. To extract the ID from the dictionary object, enter the following code.
# Extract the unique study space ID from the selected study space object
ss_id = ss_obj['id']
print(study_space)
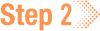 Retrieve file IDs and download files to your IDE
Retrieve file IDs and download files to your IDE
To ensure that you work with the intended datasets, first identify their IDs (from an advanced search, for example), and then download them using a reader method like read_files(), read_samples(), or cache_files(). Downloading the files creates a local copy of the data and allows the system to track which files have been accessed in your current session.
NOTE
If no_file_set is not declared, a file set containing the uploaded files will be created in your study space. If you prefer not to have file sets created automatically, set no_file_set to True.
1. Identify your file ID(s). You can list as many as you need, separated by commas (for example, ['ID1', 'ID2', 'ID3']).
# Pass in file ID(s)
files = ['4613f981-127e-4b07-a437-6f2d814eac9d']
2. Download files to your local environment (the working directory of your IDE). You have several options, depending on your workflow. When in doubt, use cache_files().
A. Use cache_files(). To return absolute path(s) to your downloaded files, with no attached metadata, call cache_files().
# Cache the specified files
hp.cache_files(files)
B. Use read_files(). To return file content with its associated metadata, call read_files(). For details, see Use the Read Files SDK Method.
# Read the specified files and retrieve metadata
hp.read_files(file_list=files)
C. Use read_samples(). To return structured sample data, such as rows from a CSV file, call read_samples(). For details, see Use the Read Samples SDK Method (Tutorial).
# Read sample data from files
hp.read_samples(sample_ids=files)
3. When prompted to select your study space, find it in the list and enter the corresponding number into the field at the bottom, as shown in the following image.
4. If you provided a sample ID or an empty list as an input, supply sample IDs for each uploaded file.
|
This prompt ensures that you provide the sample metadata necessary for reproducibility and advanced search functionality. Enter the sample IDs as a comma-separated list, as in the following image, or enter "" to upload without a sample association.
 Upload files to your study
Upload files to your study
To make your data accessible for analysis or sharing, upload your results to the study space.
1. To upload your results file(s), replace the file path and input file IDs as necessary. A successful upload will print out a trace id.
# Upload results file(s) to specified study space
hp.upload_files(
files=['input/2842984779/cohorts/4613f981-127e-4b07-a437-6f2d814eac9d/hise-example.txt'],
study_space_id=ss_id,
title='A demo upload',
input_file_ids=files
)
 Track the status of your file uploads
Track the status of your file uploads
1. To track the status of an upload files call, check the IDE for an error message or success notification, as shown in the accompanying image.

2. For detailed information, return to HISE:
A. Under RESEARCH, click the card for your IDE. A tag indicates whether the call has succeeded, failed, or is still in progress, and the Upload file logs show the status of all recent calls.
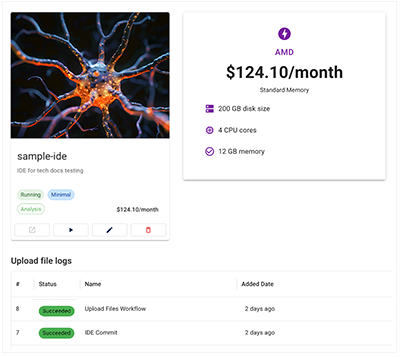
B. If you used Fast Mode to upload files to an IDE, a small blue tag appears next to the IDE in the list. For details, see Use Fast Mode (Tutorial).

C. For granular information about your file uploads, check the IDE Instances page in the COLLABORATION SPACE. It displays an upload files workflow banner, list view, and detail view. For details, see Work with Studies (Tutorial).
Tips and Troubleshooting
![]() Use Conda, not Pip, for package installation
Use Conda, not Pip, for package installation
Conda creates a snapshot of the tools and resources necessary to re-create scientific or data analytic results. It captures not only the results themselves, but also the environment in which the steps were taken or computations made. In addition, using pip instead of Conda for installation causes conflicts in the upload_files() process. The uploaded item will not be attached to your study in the HISE Collaboration Space.

Note: For the HISE SDK, install with pip. To preserve reproducibility and avoid errors, use Conda to install all other scientific packages and dependencies. |
 Use batch uploads to avoid timeouts
Use batch uploads to avoid timeouts
Timeout errors usually occur when you try to upload a large number of files or a large total data volume in a single operation. The system is unable to process the data within the allotted time, resulting in a timeout. Divide your upload into smaller batches, with fewer files per call. Instead of consolidating all research activities into a single IDE, create separate notebooks for specific purposes, such as preprocessing, predictive modeling, and visualization. For information on space limitations, see the FAQs document.
Set the files and input_file_ids parameters as lists
The files and input_file_ids parameters must be set as lists even if you upload only one file. The files list should contain absolute file paths–not just filenames or relative paths. To obtain these paths, use cache_files(), which downloads the specified files and stores them locally in the cache directory, returning their locations. The input_file_ids list includes the IDs of all files used to generate the result files. This ensures traceability and reproducibility, clarifying which input files yielded the uploaded results.
Supply either study_space_id or project
The upload_files method lets you specify certain parameters in alternative ways. To indicate where files should be uploaded, for example, you can provide either a study_space_id or a project (highlighted)–but not both. If you're not sure which parameter is required or how to format it, use help(hp.upload_files) to review the SDK help documentation, as shown in the following image. In addition, check the HISE documentation shown in the Related Resources section at the bottom of this page.